For any given machine learning problem, numerous algorithms can be applied and multiple models can be generated. This blog post will be focusing on practical approach that can be applied to most machine learning problems. Let’s get started.
First of all, categorize your problem. It’s possible to categorize tasks by input or output.
By input:
- If you have a set of labeled data or can prepare such a set, it is the domain of supervised learning.
- If you still need to define a structure, it’s an unsupervised learning problem.
- If you need the model to interact with an environment, you will apply a reinforcement learning algorithm.
By output:
- If the output of the model is a number, it’s a regression problem.
- If the output of the model is a class and the number of expected classes is known, it’s a classification problem.
- If the output of the model is a class but the number of expected classes is unknown, it’s a clustering problem.
Understand your data
The process of choosing the algorithm isn’t limited to categorizing the problem. You will also need to inspect your data; this helps in choosing the right algorithm for the problem. Some algorithms can work with smaller sample sets while others require a huge number of samples. Certain algorithms work with categorical data while others like to work with numerical input.
Augment your data
After you might have pre-processed and cleanse your data, the next is feature engineering. Feature engineering is the process of going from raw data to data that is ready for modelling. It can make the model easier to interpret, capture more complex relationships, reduce data redundancy and dimensionality and rescale variables.
Find the available algorithms
Now that you are clear about where you stand, you can identify the algorithms that are applicable and practical to implement using the tools at your disposal. Some of the factors affecting the choice of a model include:
Whether the model meets the business goals?
How much pre-processing the model needs?
How accurate the model is?
How long does the model take to make predictions?
How scalable the model is?
Types of machine learning tasks
Supervised learning
Unsupervised learning
Reinforcement learning
Supervised learning
In supervised learning, you train your model on a labeled dataset that means we have both raw input data as well as its results. We split our data into a training dataset and test dataset where the training dataset is used to train our network whereas the test dataset acts as new data for predicting results or to see the accuracy of our model. Hence, in supervised learning, our model learns from seen results the same as a teacher teaches his students because the teacher already knows the results. Accuracy is what we achieve in supervised learning as model perfection is usually high.
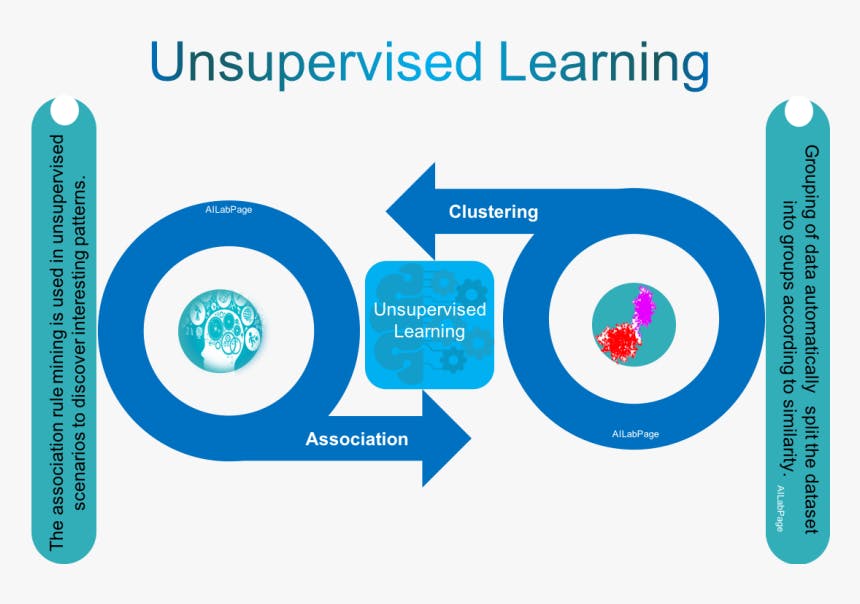
Unsupervised learning
Unsupervised learning refers to the use of artificial intelligence (AI) algorithms to identify patterns in data sets containing data points that are neither classified nor labeled. The algorithms are thus allowed to classify, label and/or group the data points contained within the data sets without having any external guidance in performing that task. In other words, unsupervised learning allows the system to identify patterns within data sets on its own.
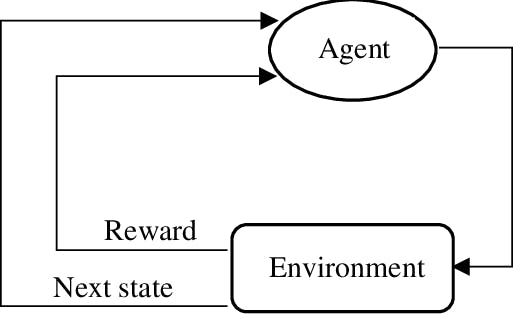
Reinforcement learning
Reinforcement Learning(RL) is a type of machine learning technique that enables an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences. Though both supervised and reinforcement learning use mapping between input and output, unlike supervised learning where feedback provided to the agent is correct set of actions for performing a task, reinforcement learning uses rewards and punishment as signals for positive and negative behavior.
Commonly Used Machine Learning Algorithms
1.Linear Regression
Linear regression is a statistical method that allows to summarize and study relationships between two continuous (quantitative) variables: One variable, denoted X, is regarded as the independent variable. The other variable denoted y is regarded as the dependent variable. Linear regression uses one independent variable X to explain or predict the outcome of the dependent variable y, while multiple regression uses two or more independent variables to predict the outcome according to a loss function such as mean squared error (MSE) or mean absolute error (MAE). So whenever you are told to predict some future value of a process which is currently running, you can go with a regression algorithm. Despite the simplicity of this algorithm, it works pretty well when there are thousands of features, for example, a bag of words or n-grams in natural language processing. More complex algorithms suffer from overfitting many features and not huge dataset, while linear regression provides decent quality. However, is unstable in case features are redundant.
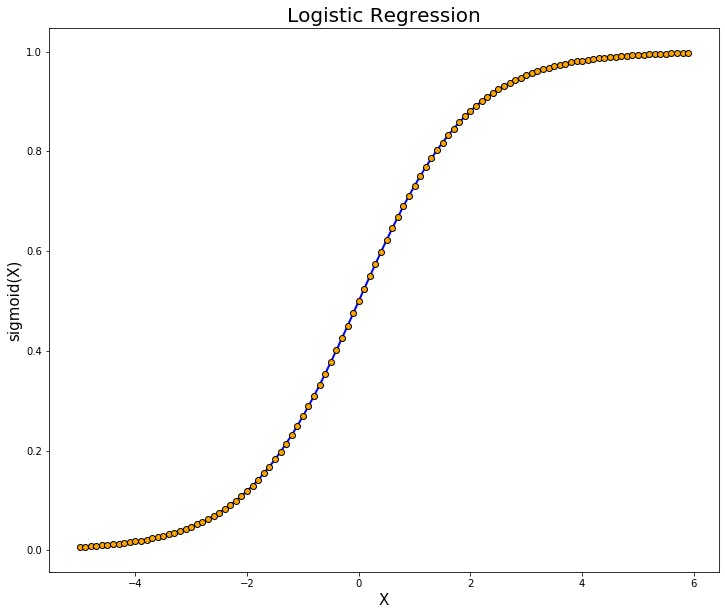
2.Logistic Regression
Don’t confuse this classification algorithm with regression methods for using regression in its title. Logistic regression is a classification algorithm. It is used to predict a binary outcome based on a set of independent variables. What does this mean? A binary outcome is one where there are only two possible scenarios—either the event happens (1) or it does not happen (0). Independent variables are those variables or factors which may influence the outcome (or dependent variable). Logistic regression is the correct type of analysis to use when you’re working with binary data. You know you’re dealing with binary data when the output or dependent variable is dichotomous or categorical in nature; in other words, if it fits into one of two categories (such as “yes” or “no”, “pass” or “fail”, and so on).
3.K-means
K-means clustering is one of the simplest and popular unsupervised machine learning algorithms. You’ll define a target number k, which refers to the number of centroids you need in the dataset. A centroid is the imaginary or real location representing the center of the cluster. Every data point is allocated to each of the clusters through reducing the in-cluster sum of squares. In other words, the K-means algorithm identifies k number of centroids, and then allocates every data point to the nearest cluster, while keeping the centroids as small as possible. The ‘means’ in the K-means refers to averaging of the data; that is, finding the centroid.
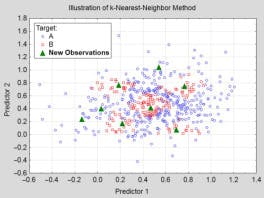
4.KNN
K-Nearest Neighbors is a machine learning technique and algorithm that can be used for both regression and classification tasks. K-Nearest Neighbors examines the labels of a chosen number of data points surrounding a target data point, in order to make a prediction about the class that the data point falls into. K-Nearest Neighbors (KNN) is a conceptually simple yet very powerful algorithm, and for those reasons, it’s one of the most popular machine learning algorithms. Let’s take a deep dive into the KNN algorithm and see exactly how it works. Having a good understanding of how KNN operates will let you appreciated the best and worst use cases for KNN
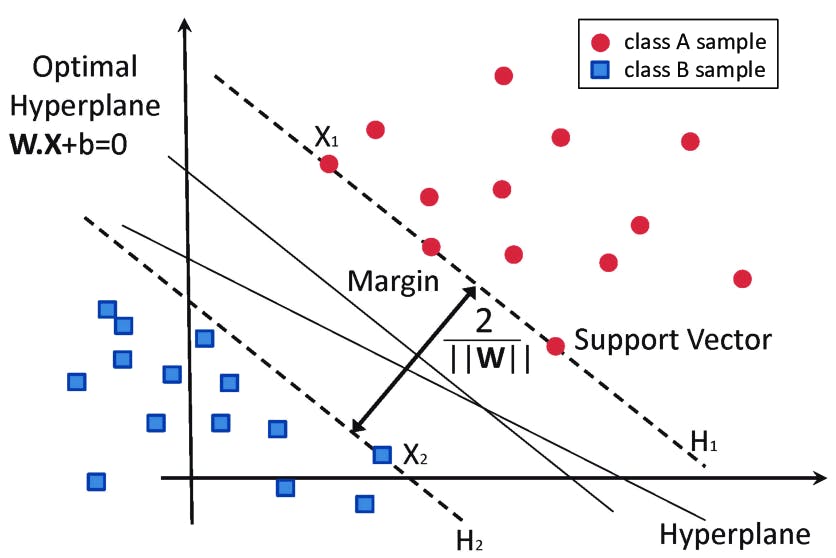
5. Support Vector Machine
SVM is one of the most popular supervised learning algorithms, which is used for classification as well as regression problems. However, primarily, it is used for Classification problems in machine learning. The goal of the SVM algorithm is to create the best line or decision boundary that can segregate n-dimensional space into classes so that we can easily put the new data point in the correct category in the future. This best decision boundary is called a hyperplane. SVM chooses the extreme points/vectors that help in creating the hyperplane. These extreme cases are called as support vectors, and hence algorithm is termed as Support Vector Machine. Suppose we see a strange cat that also has some features of dogs, so if we want a model that can accurately identify whether it is a cat or dog, so such a model can be created by using the SVM algorithm. We will first train our model with lots of images of cats and dogs so that it can learn about different features of cats and dogs, and then we test it with this strange creature. So as support vector creates a decision boundary between these two data (cat and dog) and choose extreme cases (support vectors), it will see the extreme case of cat and dog. On the basis of the support vectors, it will classify it as a cat.
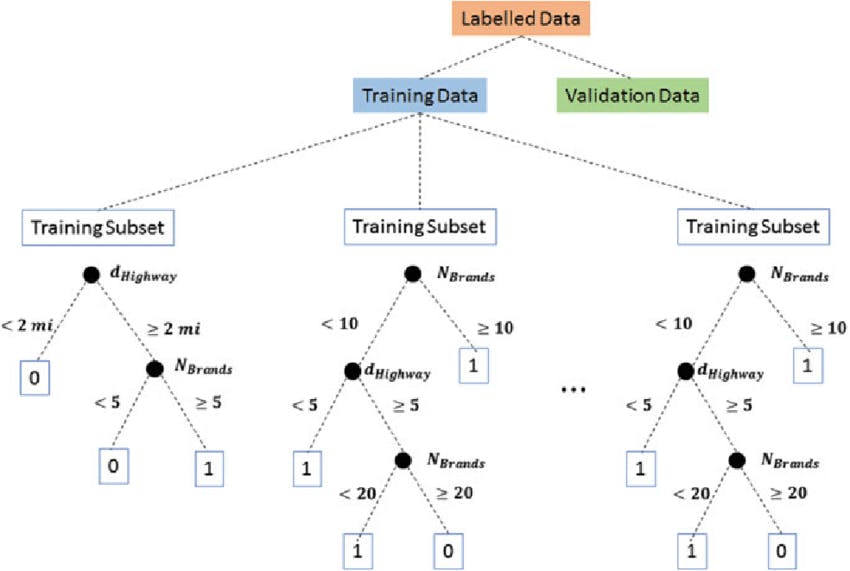
6.Random Forest
Random forest is a flexible, easy to use machine learning algorithm that produces, even without hyper-parameter tuning, a great result most of the time. It is also one of the most used algorithms, because of its simplicity and diversity (it can be used for both classification and regression tasks). In this post we'll learn how the random forest algorithm works, how it differs from other algorithms and how to use it.Random Forest is an ensemble of decision trees. It can solve both regression and classification problems with large data sets. It also helps identify most significant variables from thousands of input variables. Random Forest is highly scalable to any number of dimensions and has generally quite acceptable performances. Then finally, there are genetic algorithms, which scale admirably well to any dimension and any data with minimal knowledge of the data itself, with the most minimal and simplest implementation being the microbial genetic algorithm. With Random Forest however, learning may be slow (depending on the parameterization) and it is not possible to iteratively improve the generated models Random Forest can be used in real-world applications such as: Predict patients for high risks Predict parts failures in manufacturing Predict loan defaulters
7.Neural Networks
A neural network is a series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. In this sense, neural networks refer to systems of neurons, either organic or artificial in nature. Neural networks can adapt to changing input; so the network generates the best possible result without needing to redesign the output criteria. The concept of neural networks, which has its roots in artificial intelligence, is swiftly gaining popularity in the development of trading systems. Neural networks are a series of algorithms that mimic the operations of a human brain to recognize relationships between vast amounts of data. They are used in a variety of applications in financial services, from forecasting and marketing research to fraud detection and risk assessment. Use of neural networks for stock market price prediction varies.